Courses
Discover thousands of courses from top institutions and platforms worldwide
Level
Course Type
Duration

Udacity
Advance your tech career by learning to design, deploy, and maintain reliable, scalable systems through this Nanodegree. Featuring real-world projects, practical tools, and personalized expert feedback.

Udemy
Job of SRE in DevOps What you'll learn: This course is a one stop shop for every IT professional who wants to refresh their SRE knowledge or anyone who wants to understand the SRE workBasic understanding of IT along with in detail explanation of SRE life in DevOps modelIssue debugging sessionsIn details section for KubernetesQuick Summary of entire course at the end along with course material This course is for both beginners and experts who want to brush up their knowledge about SRE. This tutorial will guide you to understand responsibilities of SRE and the criticality of this role. You will be able to answer how operations support team contribute in Agile framework under DevOps model and how the balance between releasing new features and making sure that they are reliable for its consumers. This is achievable due to understanding of how applications work, which are the important elements you need to look at while working in an application, deep understanding of how monitoring tools work and their usage in your application based on requirement. In this course the students will learn about few of the widely used tools in monitoring. This course will also touch base the incident and change management work which SRE needs to perform as part of their role. The contents of this course are: what is an information technology system, understanding an application, who are the users of these applications, how different teams are structured in an application, roles of SRE in DevOps model, levels of production support, important elements for SRE to consider in their day to day work to keep the ship sailing, one of the most important role - Issue debugging and at last we will summarize what we have learned in this course.
IBM Training
The Associate SRE Curriculum allows a learner to start their SRE education with a strategic focus on the terminology, skills, tools, and processes from an IBM Cloud perspective, and dives into important SRE topics, such as incident management, observability, troubleshooting, operations, deployments, and security.

edX
“This course will soon be retired" Build the skills and knowledge required to work as a Site Reliability Engineer, using IBM Cloud environments and tools. This interactive course features practice exercises and real-life scenarios as you explore the content. You will also discover the tools and SRE principles needed to manage enterprise workloads in IBM Cloud environments. Upon successful completion of IBM Cloud Associate SRE Curriculum, learners enrolled in the Verified Certifcate Track will receive an edX certificate as well as a code for 50% off the IBM Certified Associate SRE- Cloud v2 certification exam. Upon receiving a passing score on the exam, the IBM Certified Associate SRE - Cloud v2 certification will be awarded by Credly.
IBM Training
Advance your skills to work as an SRE with professional-level training and certification from IBM. Gain knowledge with IBM Cloud environments and tools and practice exercises in a virtual lab environment.This interactive learning pathprovides approximately 30-35 hours of content.You’ll renew your operations, software engineering and systems administration skills; and learn the monitoring and incident management tools needed to manage enterprise workloads in IBM Cloud environments. The IBM Cloud Professional Site Reliability Engineer learning path plus practical experience will prepare you for the IBM Cloud Professional Site Reliability Engineer certificationexam.The IBM Professional Certification program is designed to validate your skills and skill levels. IBM certifications demonstrate your expertise to employers and colleagues.Explore more IBM Cloud learning paths and certifications.

YouTube
Explore how OpenShift engineers at Red Hat apply site reliability engineering (SRE) principles to continuous integration at scale in this 36-minute DevConf.US 2024 talk. Discover strategies for balancing risk with measurable objectives in CI processes, and learn how to adapt these techniques for your team's needs. Gain insights into managing large volumes of CI data, addressing seemingly random test failures, and navigating the pressure to prioritize feature delivery over testing. Ideal for developers and engineers looking to enhance their CI practices with proven SRE methodologies.

A Cloud Guru
Hello, and welcome to Reliability Engineering Concepts. This is an introductory course, no previous experience is required. This course is intended for students who like to learn more about site reliability engineering.In the first part of this course, we discuss the concepts for site reliability including understanding the Site Reliability Engineer role, supporting site reliability, the differences and similarities between DevOps and a SRE, and how SREs are organized in teams. In the second part of the course, we review the terms and definitions associated with SRE. We cover SLI, SLO, and SLA, measuring reliability, and the tools used by SREs.

YouTube
Discover the inspiring journey of a student's transformation into a Site Reliability Engineer (SRE) who embraces CNCF technologies in this 24-minute conference talk. Follow Jacob Valdemar Andreasen's path from a software technology student to a Certified Kubernetes Administrator at Lunar. Learn how he navigated the CNCF ecosystem, contributed to open-source projects, and gained expertise in Kubernetes, Linkerd, Flux, Fluent Bit, Prometheus, and Backstage. Explore the opportunities and challenges faced by aspiring platform engineers, including internship experiences, documentation contributions, and networking within the CNCF community. Gain insights on effective learning strategies, joining tech communities, studying courses, and presenting at events. Use this talk as a roadmap to kickstart your own career in cloud-native technologies and platform engineering.

A Cloud Guru
Hello! If you are interested in becoming a Site Reliability Engineer (SRE) with the Google Cloud Platform (GCP), then this is the right place to start! The same goes if you are interested in passing Google’s Professional Cloud DevOps Engineer certification exam because those two things are very closely aligned.This particular course is all about starting things off. It’s all about laying the foundation for the rest of your learning journey, which will continue in the series of other courses that make up this certification path.This course will cover: The role of DevOps Engineer/SRE: What do the terms mean and what is expected of a person who fills such a role? The context for this role: What is the business of software development? The scope of the certification that Google has defined: What is the outline of the exam? How you can move forward to learn this stuff and get certified, and who are we (the Training Architects) who will guide you through that?I hope you’ll join us on this exciting learning journey and become a DevOps Engineer/SRE!

YouTube
This 22-minute video from Dynatrace explores how Cloud Native Site Reliability Engineers can maintain continuous compliance in their systems. Learn how to detect, prioritize, and remediate security and compliance findings that violate standards like DORA, NIST, CIS, or STIG. Watch Michiel de Lepper, Product Manager at Dynatrace, demonstrate how Dynatrace Security Posture Management provides continuous insights for improving security posture and addressing compliance issues, including misconfigurations and regulatory assessments. Discover how compliance data stored in Grail can be leveraged beyond the Security Posture Management App through custom reporting, automation, and integration with SRE processes and tools. The video covers introduction to the concepts, detailed explanation of the Security Posture Management tool, assessment result analysis, data visualization in dashboards, and using DQL in notebooks for advanced compliance monitoring.

YouTube
Explore the world of event-driven architectures in this 57-minute GopherCon 2021 talk by Daniel Selans. Dive into the intricacies of building reliable distributed systems using Go, covering essential topics such as event-driven design principles, Go's suitability for distributed systems, message systems like Kafka and RabbitMQ, and the benefits of using protobuf. Learn about recommended libraries and patterns, and gain practical insights through a code demo featuring Docker Compose setup, consumer functions, order processing, and automatic recovery. Understand who should consider or avoid event-driven architectures, and discover how to achieve "reliability nirvana" in your Go-based distributed systems.

Google Cloud Skills Boost
Service level indicators (SLIs) and service level objectives (SLOs) are fundamental tools for measuring and managing reliability. In this course, students learn approaches for devising appropriate SLIs and SLOs and managing reliability through the use of an error budget.

Coursera
Service level indicators (SLIs) and service level objectives (SLOs) are fundamental tools for measuring and managing reliability. In this course, students learn approaches for devising appropriate SLIs and SLOs and managing reliability through the use of an error budget.

Pluralsight
Site Reliability Engineering is the implementation of efficient DevOps. This course will teach you the theory and practice of SRE in the real world. It also explains in detail the incident response and change management processes. Site Reliability Engineering is the implementation of efficient DevOps. In this course, Implementing Site Reliability Engineering (SRE) Reliability Best Practices, you’ll learn to implement Site Reliability Engineering best practices. First, you’ll explore managing incident response, which is a vital part of service management. Next, you’ll discover the steps to set up an efficient change management process. Finally, you’ll learn how to identify the best solutions for several common technical issues such as DNS, load balancing, health checks, and distributed consensus. When you’re finished with this course, you’ll have the skills and knowledge of Site Reliability Engineering needed to effectively manage your application or service.
YouTube
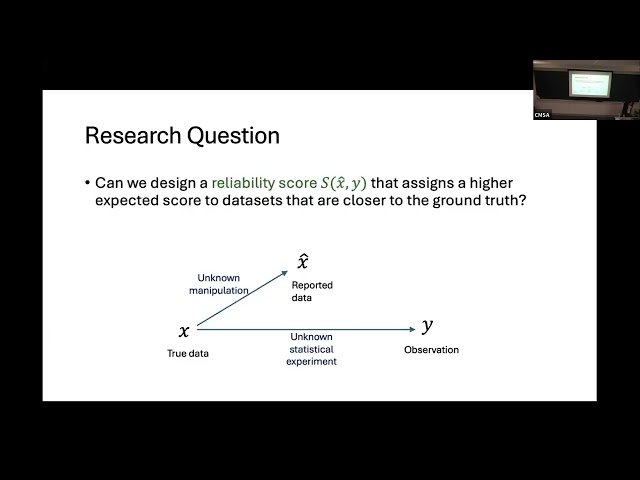
Learn about data reliability scoring methods for assessing dataset trustworthiness in this conference talk from Harvard's Center of Mathematical Sciences and Applications. Explore the challenge of evaluating data quality when dealing with potentially noisy, biased, or strategically manipulated datasets without access to ground truth. Discover the Gram Determinant Score, a novel reliability measure that uses only reported data and auxiliary observations to assess how well datasets align with unobserved truth. Examine the theoretical foundations and provable guarantees of this scoring method, including its ability to preserve natural reliability orderings. Review experimental results demonstrating the score's effectiveness in capturing data quality across synthetic noise scenarios and contrastive learning embeddings applications. Gain insights into strategic data reporting challenges and statistical approaches for reliability assessment in data-driven decision making contexts.

YouTube
Explore strategies to maximize Azure reliability in this comprehensive 47-minute video tutorial. Learn about resiliency basics, blast radius management, multi-region deployments, and global load balancing. Dive into limit considerations, change roll-out strategies, monitoring best practices, and permission management. Discover essential security measures and operational hygiene techniques to ensure optimal Azure performance. Gain valuable insights from John Savill's Technical Training, complete with practical examples and key resources for further learning on Azure mission-critical guidance and certification paths.

YouTube
Explore strategies for enhancing the reliability of bpftrace in this informative conference talk from the Linux Plumbers Conference. Delve into the challenges faced by bpftrace users and developers, and learn about innovative approaches to improve its stability and performance. Gain insights into potential solutions for common issues, best practices for implementation, and future directions for bpftrace development. Discover how these improvements can lead to more robust and dependable system tracing and debugging capabilities in Linux environments.

YouTube
Learn essential strategies for becoming a more effective Site Reliability Engineer in this conference talk from Stripe developer Julia Evans at SREcon17 Americas. Master practical approaches to debugging complex problems, including reading Linux kernel source code and leveraging specialized debugging tools. Discover why asking fundamental questions is a crucial skill, and understand how aligning with organizational needs can dramatically improve your impact. Gain confidence in contributing value as a developing SRE professional, even while still building expertise. Through real-world examples and practical insights, explore proven techniques for solving challenging infrastructure issues and collaborating effectively with teammates.

YouTube
Explore the fundamentals of Site Reliability Engineering (SRE) practices in this 50-minute Linux Foundation webinar. Delve into the trio of crucial measurements for maintaining a reliable and robust platform: SLAs, SLOs, and SLIs. Gain insights into establishing a culture of reliability and navigating your reliability journey. Learn about the three pillars of reliability, complex systems, and the concept that slowness is the new downtime. Compare DevOps and SRE approaches, understand SLA objectives and indicators, and discover the four golden signals of infrastructure management. Examine the current state of affairs in reliability, explore blameless practices, and understand the importance of root cause analysis. Cover topics such as availability, DevSecOps, and the role of different groups in leading reliability efforts.

YouTube
Explore site reliability engineering practices through a human-centric perspective in this insightful conference talk. Discover how combining SRE with HumanOps can enhance team well-being and improve organizational communication. Learn to apply reliability engineering concepts to benefit the engineers on-call, incorporate human elements into error budgets, and leverage SRE practices to foster a healthier work environment. Gain valuable insights on transforming platform building and operations while facilitating more meaningful discussions about availability, service-level objectives, and cost.